

*These are my own ramblings and nothing I say is officially supported by VMware!*
So HCX does have a DR feature. It does not get talked about much, because at VMware if you are talking fully-fledged DR you will be looking into SRM and the new offering VCDR.
The HCX DR service uses vSphere Replication (VR) under the hood in the same way, SRM can use vSphere Replication. The main difference is that the IX appliance in the service mesh is the vSphere Replication Manager.
SRM does full-on DR orchestration, failing over VMs in a specific order, with recovery plans, HCX does not do any of that.
When I have talked to GSS and some customers, I have discovered that customers like using this to help migrate big VMs, that are multiple TB in size.
Customers have found using Bulk Replication with large VMs a bit daunting, as if there is an issue with the cutover, the migration can fail. Yes, you now have the seeding option, but the bit by bit checksum check that then happens can take days to complete on a very large VM, which is far from ideal. I mean that is still better than resending all of the replication data again, but it’s not ideal for some customers.
So HCX DR allows you to replicate the VM, using various levels of RPO like you would with normal vSphere Replication. Remember here that Bulk Migration within HCX has a non-configurable RPO of 2 hours. With HCX DR you can set it from 5 mins to up to 24 hours, just like with normal VR.
You also have the option to use Point In Time (PIT) snapshots at the destination, this has been a feature of native VR for a while, every time the VM is synced, it is added to a snapshot at the destination, allowing you to recover the VM to various points in time.
HCX DR also allows you to use quiescing using VMware Tools, allowing you to get some OS-level consistency if the VM supports it. One thing to bear in mind when using this option, vSphere Replication will use a normal VMware snapshot for Windows VMs when doing application-level quiescing, which VR normally doesn’t do as it works down at the kernel level. With Linux VMs if they support quiescing it is done in the OS and no normal VMware snapshot is taken, as shown below:


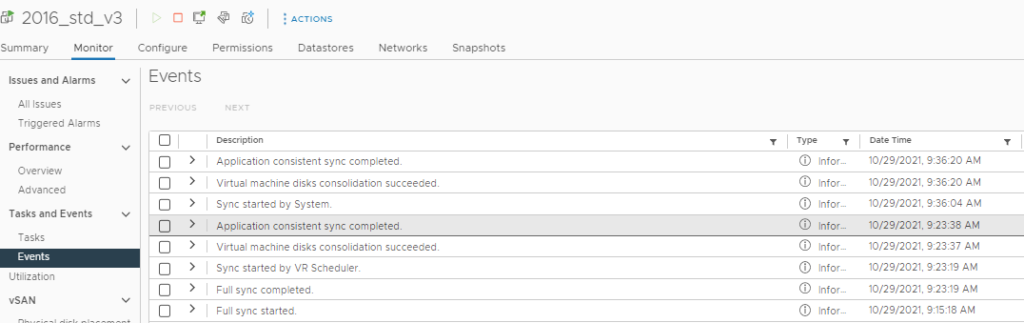
As you can see in my testing with Linux and Windows 10 it does file-level quiescing and as a result, does not use standard VMware snapshots. In my test with Windows Server 2016 it does application level quiescing and does not use a normal snapshot.
A few things to bear in mind when using the quiescing option:
- Quiescing for vSphere Replication and backup operations for the same virtual machine is not supported.
- When you enable quiescing, vSphere Replication first attempts application level quiescing. If application level quiescing fails, vSphere Replication attempts file-system level quiescing.
- vSphere Replication performs application quiescing on Windows Server 2008, Windows Server 2012 by creating a snapshot of the virtual machine
There are other caveats that are called out in the VR docs listed below:
https://docs.vmware.com/en/vSphere-Replication/8.4/rn/vsphere-replication-compat-matrix-8-4.html
As of this date, as far as I am aware HCX uses VR 6.0, I couldn’t find a compatibility matrix for 6.0, but the 8.4 one listed above seems to align with what I have seen in my tests. I don’t have Server 2008-2012 to test. It has a very good table I encourage you to check it out!
So the things we have discussed above are NOT available when using Bulk Migration.
You also can’t automate the use of HCX DR using PowerCLI in the same way you do Bulk Migration, as I have documented in my previous blog posts.
Now I have got the basic breakdown and comparison out of the way let’s talk about why I think it is something you should consider when moving huge VMs.
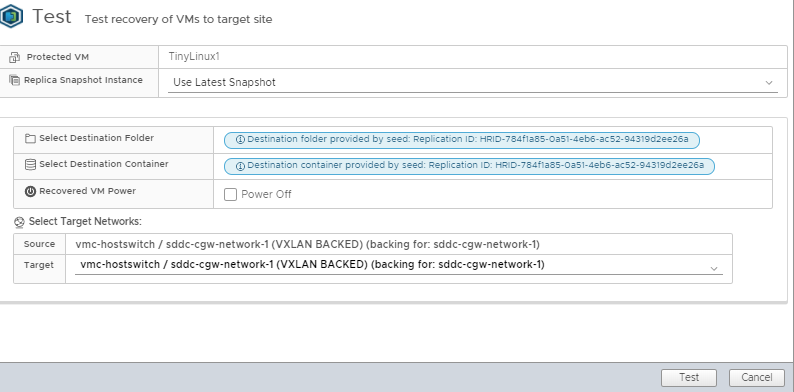
For a large VM being able to do a Test Recovery is a great idea. When you do a Test Recovery the VM will be brought online at the destination, you can pick the destination network (or no network if you choose) and you can even decide if the destination copy should be powered on or not. So you get to see if the VM will recover properly and power on and you can log into the console and do some checks, all while not breaking the replication agreement.
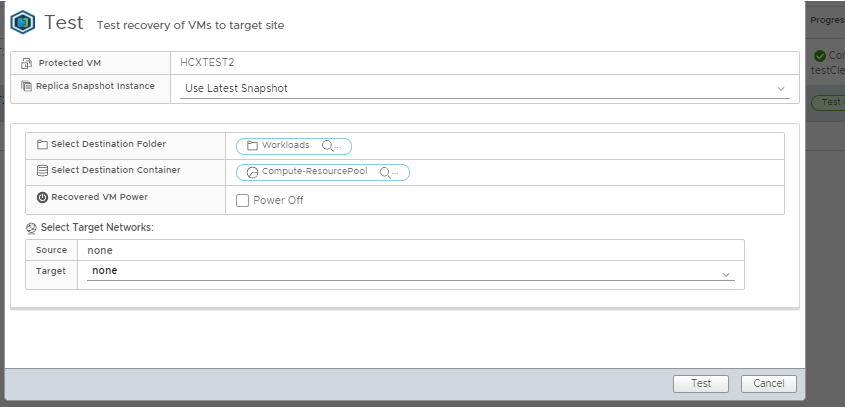
If you have selected using the PIT option I discussed early you can even specify which PIT snapshot you want to recover to, the default is the latest
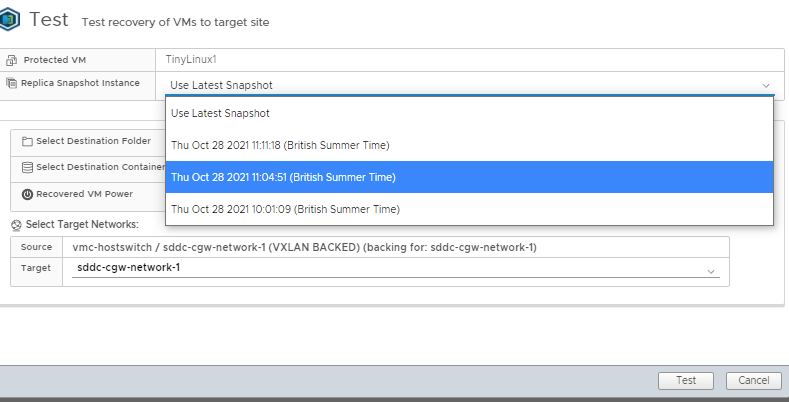
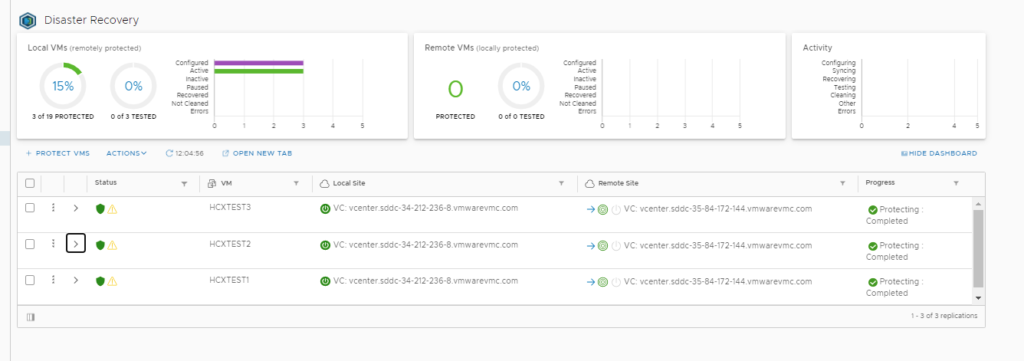
So what some customers do is they turn off all non-essential services of the VM, and select the Sync Now option :
This then makes VR sync any changes right then and there, regardless of the RPO setting. Once that is done they will then do a Test Recovery.
If you are happy you can then select the Remove option, what this does is it will remove the replication agreement and will leave the recovered VM in place. If you are happy you can then power off the source copy and archive it and then attach the destination copy to the network and away you go.
Regardless of what PIT you pick, you should not see any snapshots at the destination side, as VR sorts that out for you:
Although vSphere Replication supports up to 24 recovery points, you must set the PIT to the lowest number of recovery points that meets your business requirements. For example, if the business requirement is for 10 recovery points, you must set up vSphere Replication to save only 10 snapshots. You can set up two recovery points per day for the last five days. As a result, the consumed storage and the time needed to consolidate the snapshots after recovery are less than if you use the maximum number of recovery points.
In my testing this proved to be the case, regardless of the PIT I used to recover the VM had no snapshots at the destination
One key thing to note is the MAC address also remains the same.
If you select the Test Recover Cleanup, the VM that was powered on at the destination will be deleted and replication will continue as is. If you have used VR before at all this will all be pretty standard to you.
I did the whole test recovery and then used the remove option and as you can see the source VM is still on and the cloud VM is on as well, so be careful!
As long as you follow obvious precautions this could come in handy, at the very least you should be able to do a Test Recovery just to make sure the cutover runs correctly and if it doesn’t, it doesn’t break the replication agreement and allows you to figure out what the issue is.
As with normal VR you can just use the Recover VM option and you will get the same kind of options and you will end up with a copy of the VM at both sides, just make sure you power off the source one afterwards!
Reverse Replication is a topic that interests a lot of customers, and with HCX DR it follows the same process as VR does in general.
So once you have recovered your VM over, you will get the Reverse option available to you:
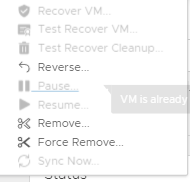
VR still holds the details of the source VM, its UUID etc and when you click reverse it checks the original vCenters inventory for the VM, and if it sees the VM is powered on you get this error:

If the VM has been removed from the inventory, even though the VM still exists on the datastore VR wont see it:

Even if you add the VM back to the inventory, it will get a new UUID and VR will not recognise it as a seed.
A clue that it is using a seed is you will see this when you do a recovery/test recovery:
When I was a vSphere Admin, I had to use VR in this way for various internal departments and it was really handy!
As long as the VM is powered off and in the inventory, VR will use it to do its checks and replicate any changed data providing you with that quick failback if you have some issue and it’s not working as well as you would have hoped!
I for one love a slow, controlled and methodical approach to dealing with complex issues, and the reason for this post is to make everyone aware that HCX DR might fit the bill for you!
Also one of my colleagues has done a youtube video on using HCX DR, its a slightly older version but the main bits are all still valid, have a look:
Give it a try!
Leave a Reply