

This article was updated on the 11th of November 2020
So as HCX has progressed over the last year, a lot of the initial things that could catch you out have been sorted and for the most part, it’s all pretty simple to deploy and get up and running.
There are times you will come across certain errors and you have to sit back and try and figure out what HCX is doing and why that error is happening, as sometimes the errors can be a bit cryptic…even when you go diving into the logs!
Service Mesh
When deploying a new Service Mesh I kept coming across this error:

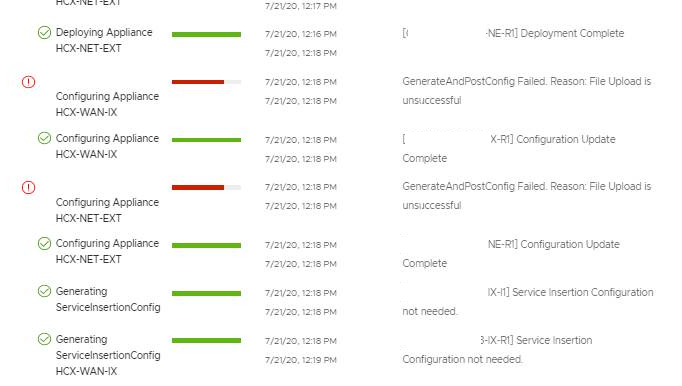
After troubleshooting with VMware support and Engineering, their first thought was that since the legacy site was on vCenter 6.5 and ESXi was on 5.5, HCX was trying to talk to the ESXi hosts in way that wouldn’t work for ESXi 5.5
But after the engineers did some further log diving it actually turned out that, this new mesh was configured to run in the ESXi Mgmt network, which is perfectly fine, but the HCX Manager Web Proxy did not have that network in its exclusion list, so automatically tried to send the traffic out the web proxy when it shouldn’t have and this caused the failure!
Layer 2 Extension
Correct Gateway details
When doing a Layer 2 Extension I was entering in the details and it kept kicking back saying it was starting the extension but nothing happened.
After racking my brains for a while and having another person check what I was doing…it became obvious.
When you are entering the gateway details and subnet mask, I was actually entering the network address and subnet mask. So instead of 10.10.10.254/24 I was putting in 10.10.10.0/24 and instead of erroring out, it took it fine and then did nothing!
This is correct:

This is not:

VDS adjustments
When doing a layer 2 extension, we were troubleshooting why we could not get any VM traffic across the link. Everything was up, tunnels were up, no firewalls blocking.
When using tcpdump on the NE appliances, we could see the test VM in the cloud reaching out to the gateway and the traffic reaching the legacy side NE appliance and then just stopping.
I did some digging and found the culprit! On the legacy side, VDS HCX creates a Trunk Port group and in that the block all ports setting was enabled (Shout out to our very own @UltTransformer for helping me with the network fault finding!).
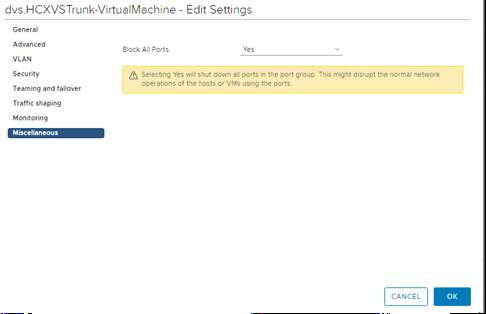
As soon as that was set to “No” everything started working. After discussing this with support, they confirmed that this is fixed in R141 and above. But it is something to be mindful of.
In my testing on R141, that setting even when set to “Yes” has no impact on the L2 appliance anymore and traffic just flows through as it should.
HCX Uplinks
HCX uses the concepts of uplinks for its service mesh appliances, they are used to send migration traffic over the WAN to the destination.
You can set HCX services meshes to use the same IP for mgmt, vSphere Replication, vMotion and uplink.
After speaking with VMware support, they have been seeing more and more cases of replications being stuck at 0% and they are now moving to the recommendation that you put uplink traffic in a different subnet to the rest, as sometimes the appliance doesn’t route traffic properly and it causes connectivity issues.
Old Way:

New Way:

Uplink is in a different subnet and uses its own IP, that way the appliances do not get confused about which gateway to use. I know a while back this was sometimes an issue and you could define a static route to mitigate it, but now it seems to prevent it from ever being an issue, this kind of separation is needed.
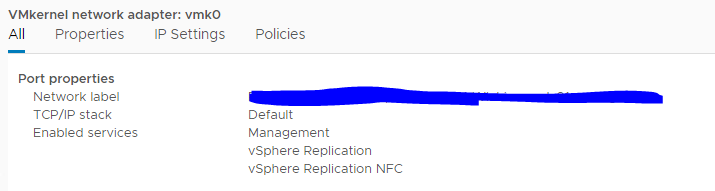
They also recommend that at the destination that you set the ESXi vmk0 to allow vSphere Replication\vSphere Replication NFC traffic. It should default to that anyway as vSphere Replication traffic has always used vmk0/mgmt vmk0 by default, but this just ensures the correct replication traffic flow.
Bulk Migration
I came across this error recently:

This error came up recently when migrating out of an ESXi 5.5 cluster. When I looked at the vCenter events I noticed this:

So replication using HCX was configured, it started fine. Then vCenter kicked off a DRS migration and then replication failed and HCX disabled replication on the VM.
I recall when working as an admin on an ESXi 5.5 environment with vSphere Replication 5.8 there was a known issue on a certain build of ESXi where a vMotion would cause vSphere Replication to fail.
it appears vSphere Replication is unable to keep track of the VM when it is moved.
So what I did is I set DRS threshold from 3 to 2, that should limit the number of migrations during the migration event, as the customer wasn’t keen on going any lower than that or disabling DRS altogether during the event.
Here is a basic idea of how the thresholds work:
What I did for subsequent migration events is use a script to set the DRS level to Manual for the VMs that would be migrated using HCX. That way only the VMs being moved out of the environment were impacted and not the whole cluster.
https://code.vmware.com/forums/2530/vsphere-powercli#579088
Import-Csv -Path C:\Temp\vmnames.csv -UseCulture | %{
Get-VM -Name $_.Name | Set-VM -DrsAutomationLevel Manual -Confirm;$false
}
From <https://code.vmware.com/forums/2530/vsphere-powercli#579088>
Or this quick and dirty way and just list the VMs in a text file
Start-Transcript
Connect-VIServer -Server <vCenter>
Get-VM -Name (Get-Content -Path e:\tmp\VMs.txt) | Set-VM -DrsAutomationLevel Manual -Confirm:$false -WhatIf
Disconnect-VIServer -Server <vCenter> -Confirm:$false
The vmnames.csv\VMs.txt file just contains a list of VM names.
Downloading the HCX Connector OVA
If you are trying to download the connector OVA after you have deployed the cloud manager, and you are using the vCenter HCX plugin to do so. I have seen multiple people report it doesn’t download.
The workaround is to log into the cloud manager directly and initiate the download request from there.
I find using the manager interface much easier than using the vCenter plugins, especially in legacy environments that don’t have full HTML5 compatibility!
HCX Upgrade Cycles
The HCX upgrade cycle is now once a month, instead of the original bi-weekly schedule. You must still stay within the N-3 version interoperability to remain supported. So if you are in build R130 and R133 was the latest you would still be supported, but as soon as R134 comes out and you stay on R130 you will now become unsupported.
HCX Upgrade Cycles
HCX B/W Limit Adjustment
When using the WAN Optimizer appliance in your service mesh, you can set a B/W limit to ensure that you do not saturate your WAN uplink. This is very handy for customers that have small WAN pipes from remote offices for example.
The issue has always been that to adjust it, you had to redeploy the whole service mesh, as the configure is applied as part of the compute profile.
Chris Dooks made a very good post of this, and we had various discussions about it, and redeploying the mesh could be problematic, esp if you already have migrations/syncs going.
So we talked about using NIOC to limit vSphere Replication Traffic and overall it works well, here is the link to his blog post on it:
HCX Cap Limit Exceeded
So I had a deployment that was using the NSX Enterprise Plus Key, this key gives you HCX Advanced features. Now the key had been put into HCX and they had been using it for months. It was perpetual and was showing as activated in HCX.
But we started randomly seeing the following error:

HCX in the admin interface on port 9443 was showing the key as active:
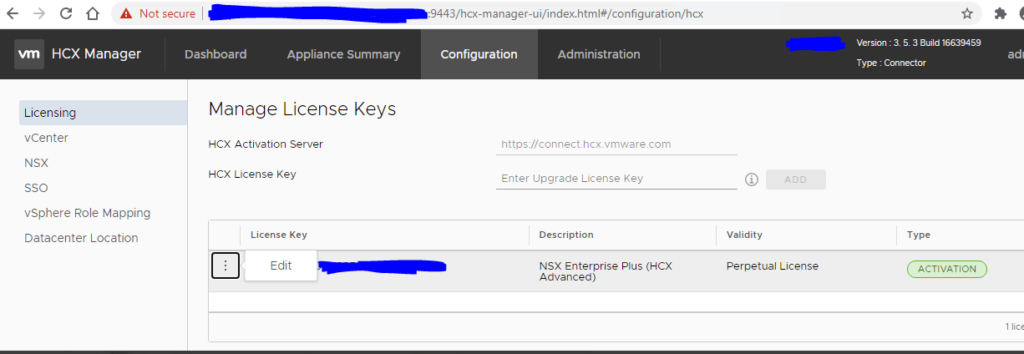
After speaking with the VMware TAM assigned to the account, it appeared that the keys had been recut and the current key had become inactive.
HCX phones home periodically to report and check the key, it is one of the few VMware products to do so and since the key was now marked as inactive, HCX had reverted to evaluation mode and in that mode, you can only do a maximum of 20 migrations in total using that key.
Once I was supplied with a new key and applied it using the edit option in the screenshot above, replications started working again!
HCX Scripting Issue
A customer was using the HCX scripts I created to configure bulk migrations and in certain sites, they were getting the following error:

This error occurs when there are duplicate VM Folders in the destination Center and you are telling HCX to put it into that folder. It gets confused!

As you can see above event though the case is different, HCX is unable to tell the difference and errors out as a result. So the workaround is to rename one of the folders and then the script will run fine.
If you are using the GUI you can pick the correct folder and avoid this issue. It appears that HCx pulls its own inventory from the Center and uses its own IDs, so cross-referencing is quite difficult…hence it is much easier to rename one of the folders and continue.
HCX Disk Size Mismatch
This is a vSphere Replication issue at its core but impacts HCX Bulk Migration since it uses VR.
You will see HCx Replication stay at 0% and you will see the following error in vCenter in the VM events:
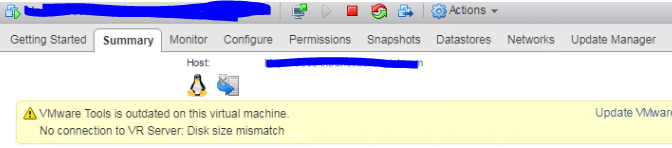

Now looking at the VM in particular you will see the VMDKs will have a very weird size:
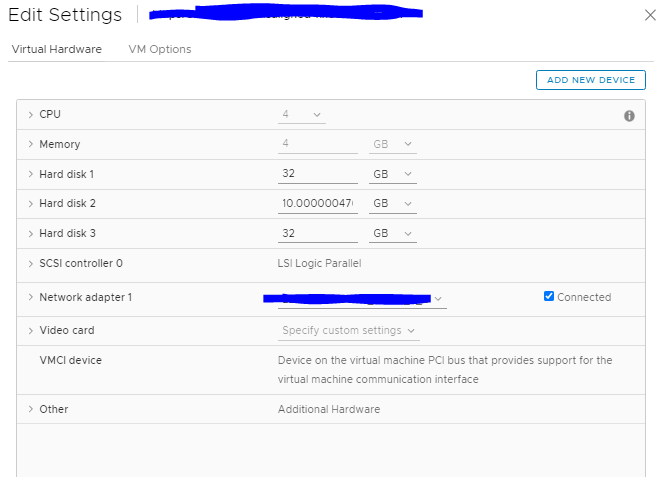
As you can see the disk 2 has a very specific size, I have found this is usually from previous P2V migrations. Generally, it doesn’t really make any difference, but VR doesn’t like it and it needs adjusting to a whole number:
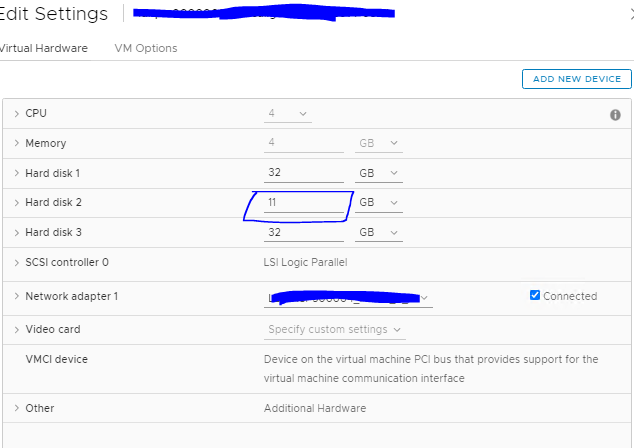
Now I have adjusted to 11 GB and now HCX will replicate the VM with no issue.
Further information can be found in this kb:
Hi Bilal. I have a scenario you mention above in which we need to limit bandwidth because we don’t want to saturate the pipe. I’ve read Chris’s article on it and that is an option. But here’s the what we ran into:
-Service Mesh deployed without WAN Optimizer
-Ran Transport Analytics and saw traffic was consuming 1 gig pipe
-enabled WAN optimizer in compute profile and set bandwidth limit to 700 Mbps
-enabled WAN optimizer in service Mesh
-WAN optimizer appliance deployed
-Ran transport analytics again and still see consumption of about 1 gig when we migrated a test VM
Why didn’t it change?