

I recently had some trouble upgrading the base esxi image on a vmware host running 6.0.0 so thought I would let you all know how I resolved it as I had the same trouble with other hosts running 5.5.0
Going through the usual process of uploading the iso to update manager and creating the baseline completed without any issues and so I migrated all live VM’s to the other host in the cluster, disabled HA on the host and popped it into maintenance mode.
When it came to remediating the update I was however faced with the following problem:
![]()
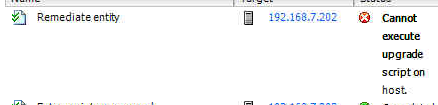
Now this is a bit of an ambiguous error, so we need to take a look at the logs to find out exactly what is causing the problem.
The best way to do this is to look at the logs on the host.
Enable SSH on the host and start the SSH service
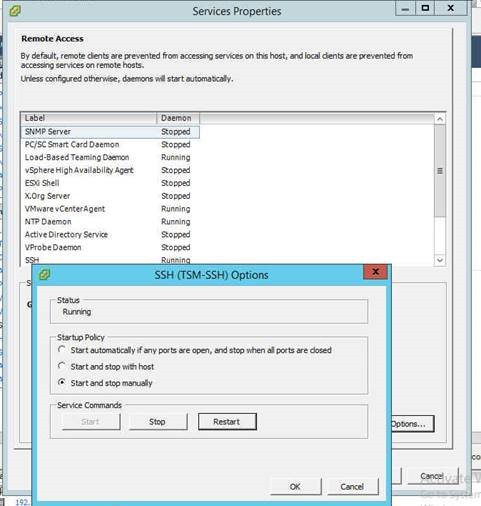
Arm yourself with WinSCP (https://winscp.net/eng/download.php) this allows you to SSH onto the host and browse the folder structure in a windows explorer style format
Fire up WinSCP, punch in the host IP address (keep port at 22) and enter the root username and password
The logs we need are located in /var/log/vua.log (there may be multiples) download these to your local machine
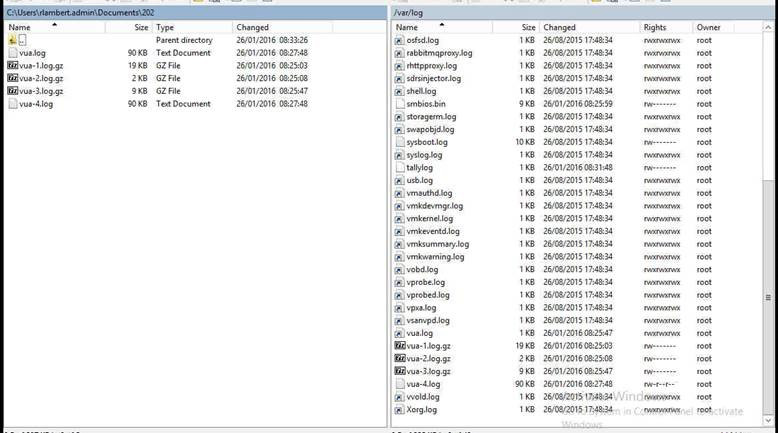
You will need to install 7-zip (http://www.7-zip.org/) or something similar to view the logs
Open up the log and scroll to the bottom.
If the issue is the same as is being experienced here you should see:
2016-01-26T08:27:48.948Z error vua[FF9300E0] [Originator@6876 sub=Default] Alert:WARNING: This application is not using QuickExit(). The exit code will be set to 0.@ bora/vim/lib/vmacore/main/service.cpp:162
This for some reason is to do with the FDM agent (former HA agent) on the host L
Now, the way to resolve this is a little unorthodox.
First of all disable HA on the cluster (be sure to take a memo of the current HA settings)
Then open up putty and SSH onto the host (putty is installed with veeam by default)
Type in the following commands:
cp /opt/vmware/uninstallers/VMware-fdm-uninstall.sh /tmp
cd tmp
chmod +x /tmp/VMware-fdm-uninstall.sh
/tmp/VMware-fdm-uninstall.sh
Reboot the host, pop it back in maintenance mode and try to remediate the update again (be prepared to wait for a while….)
![]()
Remember to re-enable HA for the cluster.
You should then have a nicely updated host![]()
Leave a Reply