

For the 2 weeks I had been having very annoying NTP sync issues on some of my VCSA and PSC appliances in one of the datacenters.
While my SSO domain and vCenter enhanced linked mode were for the most part working properly, it still bugged me that the NTP clocks on my PSC and VCSA in datacenter 1 were properly syncing with the NTP source (windows NTP source), but the NTP time on my PSC and VCSA in datacenter 2 were always off with somewhere between 3 to 7 minutes with the clocks of all my other appliances and Windows VM’s. They did how ever sync properly with each other.
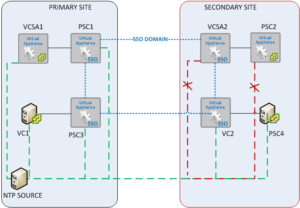 (For trouble shooting purposes, I pointed all appliances to a single NTP source in a single data center)
(For trouble shooting purposes, I pointed all appliances to a single NTP source in a single data center)
To solve this issue I tried the following things which did not solve the issue:
Step 1
- Removed ” Synchronize Guest with VM Host” in the VM properties.
- Using VAMI for the VCSA https://vcenter:5480 to set the NTP servers.
- Using VAMI for the PSC https://PSC:5480 to set the NTP servers.
- Rebooted the appliances (using shell commands)
- No luck, the NTP time on the secondary VCSA and secondary PSC remained out of sync with all other servers and devices.
Step 2
- I modified the ntp.conf file in both appliances to reflect only the NTP source which I was using for troubleshooting.
- I restarted both appliances
- No luck, the time remained syncing for like 15 seconds, then reverted back to a time sync difference of 3 to 7 minutes. Typing date in shell would actually show the correct date and time for like 3o seconds and then go out of sync again with a time difference of, you guessed it, 3 to 7 minutes with all the other servers and appliances. Very odd.
This was really getting under my skin so I decided to give my poor head some time because there was no production impact afterall.
Step 3
I have to give you a small introduction here. The previous 2 days I have been enjoying a seminar on Cisco’s Cloud Center platform, which is a topic for another post. However in that course sitting next to me was a DevOps engineer, Francois, who is very skilled in Linux and AWS. When he heard about my NTP problem on Linux estate he asked me if he could have a look into this NTP problem with me. Francois and I verified all NTP settings from a Linux perspective. Oddly enough we didn’t find any cause for the time drift.
After about 10 minutes of verifying settings he asked me the following:”Did you run an ntpq -p command yet, to see how much drift you have?” I had not, I didn’t even know the command. This command showed me that the drift (offset) between that particular PSC and the NTP time source was somewhere around 15000! Yeah this was not looking good. We went back to inspecting all basic layers of the NTP configuration. Again we didn’t find any issues with the setup.
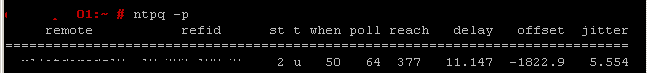
He asked me if I tried starting and stopping the NTP service itself instead of rebooting the appliances. I had to tell him I hadn’t. However I did reboot the appliances which seemed to solve this issue for some time but never on a permanent basis. We decided to start and stop the NTP service on itself anyway. You never know, right?
rcntp stop
rcntp start
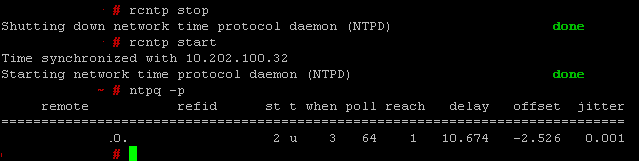
Bingo! Restarting the NTP service itself seems to solve my issues!
Addendum June 12, 2017
A couple of weeks ago I discovered that one of the domain controllers (which are setup to run NTP), the previous PDC, somehow had gotten a bit corrupt. I did not allow me to set the correct time, not allowed it me to properly sync the time with the other DCs. Once this server had been decommisioned all NTP errors have disappeared.
Kim
Kim, the below cmd doesn’t work in 6.5u1. Ntpq -p works fine though. Thanks
root@rclascvc002 [ ~ ]# rcntp stop
bash: rcntp: command not found
Tnx for the information 🙂
in 6.5 you can use
service ntpd stop
service ntpd start