

So we have now talked about AI/LLMs and Prompt Engineering, let us now move onto Fine Tuning!

Pre Training:
This is when you first start using a model and give it a VAST amount of unstructured text data. It is where the model is trained on general purpose tasks, such as predicting the next word in a sentence. The idea is it will help it develop a broad understanding of patterns and world knowledge.
Why Pre-Training Matters: Pre-training allows the model to start from a place of general language competence, saving time and computational resources when fine-tuning for more specific tasks. Pre-training on large-scale data provides the foundation, and fine-tuning adds specificity.
Fine Tuning:
This is the learning process where you use a data set of labelled examples to update and adjust the weights of the pre-trained LLM.
The main goal of fine tuning is to make the LLM proficient in a specific task or domain, such as answering customer service questions, generating legal summaries, or providing medical advice. Pre-training equips the model with general language skills, while fine-tuning refines these skills for specialised applications.
Now this is different to the one shot and multi shot inference we discussed in the previous post. The issue here is that for smaller models, it doesn’t always work, even when five or six examples are included. Second, any examples you include in your prompt take up valuable space in the context window, reducing the amount of room you have to include other useful information.
The goal of the process is to create a new version of the LLM model with updated weights that are fine tuned to the specific task you are after. The main thing to consider is that a full fine tune requires enough memory and compute to store and process all the changes and optimisations.
Doing this fine tuning can lead to the issue of Catastrophic Forgetting:
Catastrophic forgetting happens because the full fine-tuning process modifies the weights of the original LLM. While this leads to great performance on the single fine-tuning task, it can degrade performance on other tasks. For example, while fine-tuning can improve the ability of a model to perform sentiment analysis on a review and result in a quality completion, the model may forget how to do other tasks.
It is the perfect example of becoming a specialist in one area and losing skills in other areas because you haven’t done them in a long time. This to me is a very human trait!
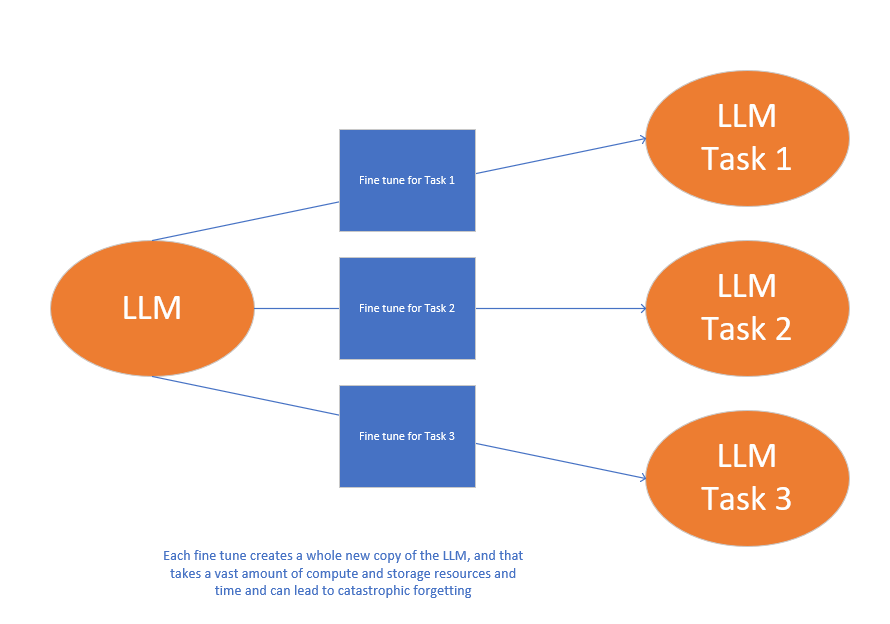
Now you may be wondering how do you avoid this issue?
- You might not have to worry about it, simply because you are training the LLM to do a specific task, so why would you be bothered if it forgot how to do other tasks? If you hired a master plumber, would you be bothered that he couldn’t do electrical work?
- You can fine tune multiple tasks at the same time, it’s more work but if you need it to be good at a few tasks this may be the way to go.
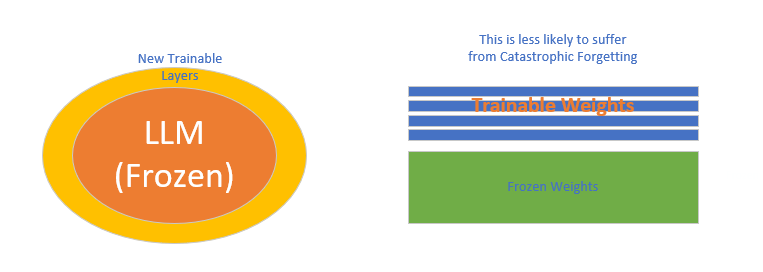
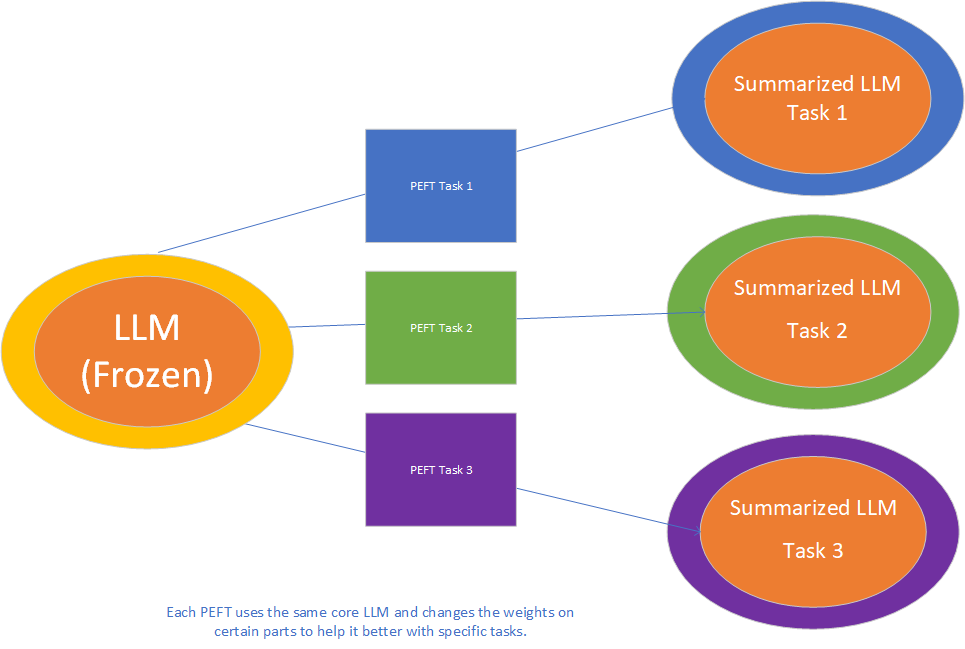
- Finally there is Parameter Efficient Fine-tuning (PEFT), now PEFT is a set of techniques that only modify a small subset of the LLMs parameters. What makes this method great is that you do not need to fine tune the WHOLE LLM, so it takes less resources.
Fine-tuning large models can be highly costly in terms of memory, time, and computational power. PEFT enables more efficient fine-tuning by focusing on a small portion of the model’s parameters, significantly reducing the resource overhead. It is particularly valuable for scenarios where you need to fine-tune LLMs repeatedly for different tasks or in environments with limited computational resources.
By using PEFT you also limit the impact of Catastrophic Forgetting, since the majority of the LLM remains unchanged.
The most common form of PEFT is Low-Rank Adaptation (LoRA), this modifies only a subset of weights in each layer by representing them as a low-rank matrix. This reduces the number of parameters needed to be updated during fine-tuning, allowing for efficient adaptation to new tasks.
Thank you for joining me today on my learning journey!
Leave a Reply