

First off, is it just me that when someone mentions AI, that I think of Ali G?

I’ve been wanting to say that for ages, now that I have got that off my chest, let’s continue!
I have started digging into the topic recently and this and any following blog posts are just going to be my ramblings on the matter and could indeed be incorrect (as I am still learning).
I’ve done a couple NVIDIA training courses on the topic so far and they are free, so please go check them out if you just want to get a high-level feel and overview of the topic! I mean let’s be honest the topic is a deep deep topic that will take a long while to get competent at. But as they always say the journey of a thousand miles starts with a single step!
AI for All: From Basics to GenAI Practice – https://academy.nvidia.com/
The key terms when it comes to Large Language Models are as follows:
Foundation/Base Models
These are the actual models that hold all the data and where the magic is held. They come in different sizes, and the larger the model isn’t necessarily the better model, it really depends on the use case.
GPT – is one of the largest models (1 trillion parameters or so it is rumored) and is the one most people know about but there are other models as well. https://openai.com/index/gpt-4-research/
BLOOM – 176 billion parameters https://huggingface.co/bigscience/bloom
FLAN-T5 – 780 million parameters https://huggingface.co/docs/transformers/main/en/model_doc/flan-t5
LLaMa – 65 billion parameters https://llama.meta.com/
PaLM – 540 billion parameters https://blog.google/technology/ai/google-palm-2-ai-large-language-model/
BERT – 340 million parameters https://huggingface.co/transformers/v3.5.1/model_doc/bert.html#overview
Now think of parameters as the model’s memory, so the more memory the model has the more sophisticated it is and the more things it can do for you.
There is no point using such a massive model if what you need could be covered by a much smaller model, it would take less space and require less resources.
You can of course create your own model, but that is time-consuming as doing anything from scratch. You might have a solid use case for this, but a lot of people will use one of the foundational models to get started
In all the testing that has gone on it is clear that the larger the model (the more parameters it has) the better the model understands and processes requests and the sooner it gets to a desired answer.
Models can be fine-tuned, so you could use a smaller model and fine-tune it and it could quite easily give you a solid result based on more focused tasks.
As with many things in life do you want a generalist or a specialist?
This brings to mind a quote…..a quote that most people do not actually know in full:
A jack of all trades is a master of none……..but is still better than a master of one.
Prompts
To use these Large Language Models, you need to use prompts:
This is where you tell the model what you want it to do, such as:
How it works is:
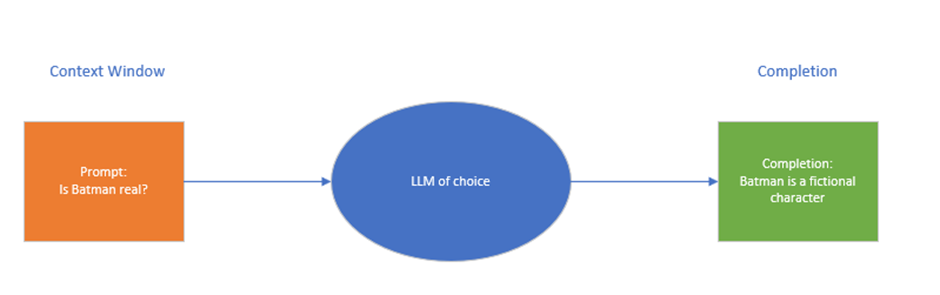
The area you type in your text prompt is called a context window.
The output from the LLM is called a completion since its completes the task and gives you a result.
I think the next blog post will be on Prompt Engineering
Leave a Reply