

So I have been deploying and testing HCX recently for a customer. This customer wants to use the HCX vMotion feature to migrate out of their legacy DCs.
Normally HCX Bulk Migration is used to move the majority of VMs out and HCX vMotion is used for the key heavy hitter VMs that you do not want to power down for XYZ reason. The main reason for this is time, Bulk Migration can move 100-200 VMs at a time quite easily as it uses vSphere Replication, but the downside is that during the cutover there is some downtime:
- VM is powered off at the source
- Off-line sync happens
- VM is powered on at the destination
You can define when the cutover happens, so you could have it happen to all the VMs at the same time or you could cut over in waves of 10/20/34/62 basically whatever figure you choose.
Most customers want to exit out of their legacy environment as quickly as possible due to ageing hardware, technical debt and the sooner they are out the sooner they can stop dealing with it and move on with their lives.
This customer is not in any particular rush and would like to keep the VMs online so that they don’t have to discuss anything with various app owners and can just crack on as needed. If they could speed it up great but it is by no means essential.
So, this has made things interesting, HCX vMotion works in a serial fashion, so it will only migrate one at a time PER SERVICE Mesh. So one way to speed it up is to use multiple service meshes so you can migrate from multiple legacy clusters to the destination and have multiple HCX vMotions on the go. The issue is the overhead of having multiple Service Mesh Appliances, if you are constrained resourcing wise at either side this can be a no go.
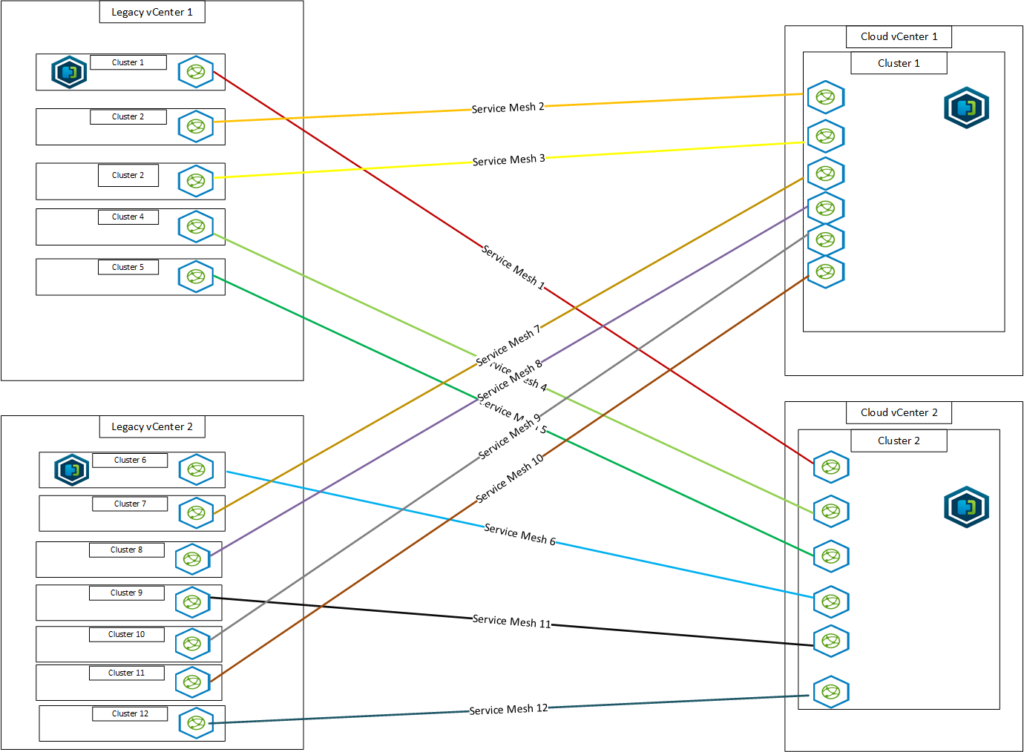
The plan is to script out the HCX vMotions and just let them run overnight/weekend and do things that way. I have said that if the time scales become tight, they should investigate if there are workloads/VMs that could accept downtime and Bulk Migration could be used…speeding things up massively!
Part of an HCX vMotion is that it maintains the EVC level of the VM, so if the source cluster is at a Sandy Bridge level, when the VM is migrated over, it will maintain that level regardless of the destination cluster being at a higher level. As with all things EVC, once you do a FULL POWER CYCLE of the VM it will then take the newer clusters EVC level. Now with per VM EVC it gets more complex but that’s outside the scope of this.
While doing some testing of the recent HCX deployment, I had some test VMs created that I could migrate between various clusters using HCX vMotion, to test if everything was working as defined. I ran into an issue where certain VMs would not migrate back to the legacy side using HCX vMotion. I spent some time discussing it with Chris Noon as I couldn’t figure out why certain VMs were impacted but others were fine.
The error I would get was:

Nothing to directly tell you it has anything to do with EVC. In my tests what I noticed was that even after a full power cycle of the VM it would still show as sandy bridge in the destination vCenter

But if you tried to migrate it back to the original source cluster it would fail, even via powercli it showed:
Name MinRequiredEVCModeKey Cluster ClusterEVCMode
—- ——————— ——- ————–
HCX-Tester4 intel-sandybridge Test-Cluster intel-haswell
So this seems to me to be a bit odd, as when you power cycle a VM it should take the cluster level EVC config (unless you have per VM EVC, but this VM is HW level 11 anyway). Even though the vCenter showed Sandy Bridge, it clearly had changed because now I could no longer to migrate it back using HCx vMotion.
I tested this numerous times, and VMs created at the cloud side, or migrated across and power cycled could no longer be HCX vMotioned back…. which of course makes perfect sense, as the EVC level is higher on the cloud side.
The only way back now would be to bulk migrate or cold migrate.
Why the EVC level did not update in vCenter I am unsure of.
Leave a Reply