

 One of the most interesting features of VSAN, is the stretched cluster capability. It is safe to say, when we first introduced the stretched cluster capability, it wasn’t 100% ready. Sure, it worked, but it needed some improvements. Meanwhile we have made several improvements and have extended the stretched cluster feature set and it is now fully functioning & enterprise ready. Of course, with great claims come great responsibilities. So because we are always dealing with customer data, I always have a conversation with the customer about the actual expectations. This is especially the case if the client is thinking about using enterprise features such as stretched clustering. Some customers have a very good understanding of business continuity others are not yet as skilled in this matter. As a pre-sales you have a responsibility to explain your customers how things are done and how some pieces fit together.
One of the most interesting features of VSAN, is the stretched cluster capability. It is safe to say, when we first introduced the stretched cluster capability, it wasn’t 100% ready. Sure, it worked, but it needed some improvements. Meanwhile we have made several improvements and have extended the stretched cluster feature set and it is now fully functioning & enterprise ready. Of course, with great claims come great responsibilities. So because we are always dealing with customer data, I always have a conversation with the customer about the actual expectations. This is especially the case if the client is thinking about using enterprise features such as stretched clustering. Some customers have a very good understanding of business continuity others are not yet as skilled in this matter. As a pre-sales you have a responsibility to explain your customers how things are done and how some pieces fit together.
That is exactly what this post is about. I have a conversation with all my customer about the failure scenarios and the mechanisms in place to handle site/component failures.
So let’s dive right into it!
Policies FTW!
First off all we need to understand what a policy is. A policy in VSAN is a set of rules that lays out the behaviour of VSAN. Parts of this rule set are:
* How many failure can I tolerate before actually loosing data? So called FTT
* How to I want to get there? Will I use raid1/5/6 across hosts?
* Do I want my data to be migrated to a secondary site when a failure happens?
* Do I want to use site affinity for some workloads?
There are more policies than these 4 but these are the most important policies for this story.
In just a few clicks you can make a policy from the vSphere web client or HML5 client. As you know, you can apply this policy to the foll VM but also to the separate pieces of a VM. So called “Objects”.
These objects are split into different components and are spread across the hosts and are maintained by VSAN in any case of of component failure.
Back to stretched clusters!
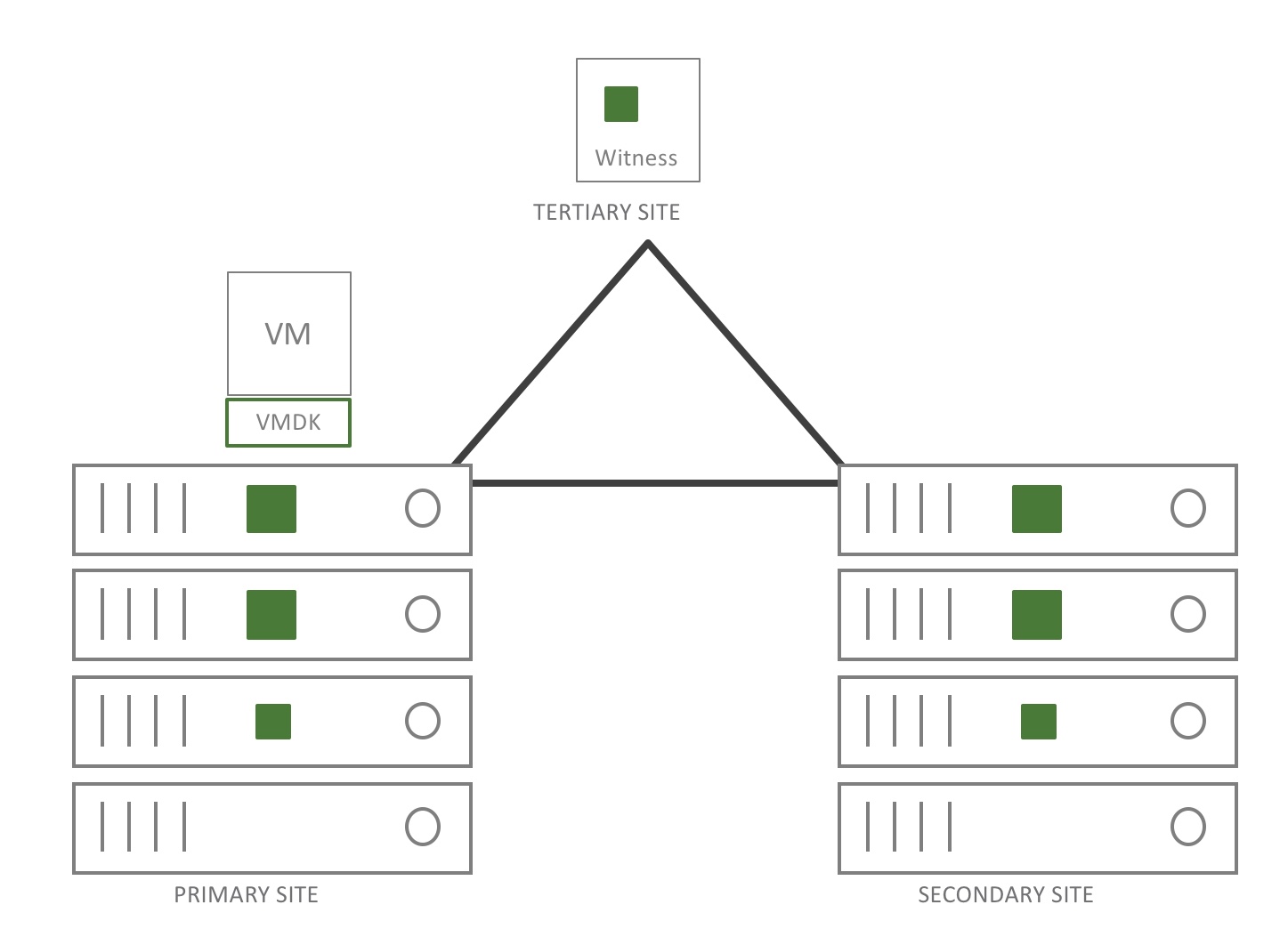
In the drawing you can see a VM in a normal state. It has a FTT of 1 in RAID1. The representation is 3 components on both sites (2 data & 1 witness) another witness is looking after the stretched cluster.
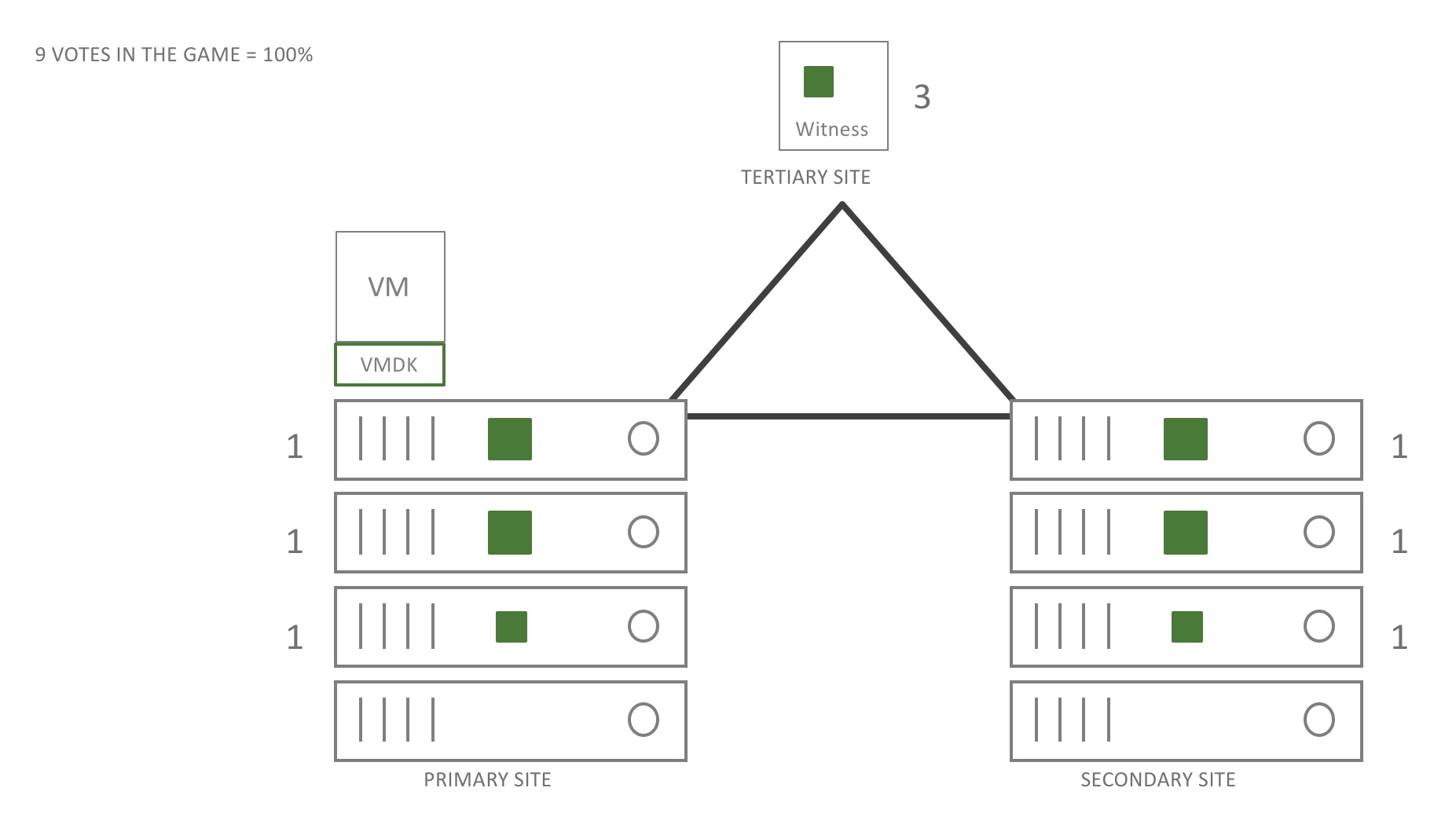
Let’s add a little more detail to this picture. All components have votes. The votes in this case are spread out over the different sites. And yes, the witness has some votes too. As a matter of fact, it has the same amount of votes to represent this particular object as the other sites. If for any reason the total number of votes would be even, VSAN would add a vote randomly. Ok, let’s now fail parts of this construct.
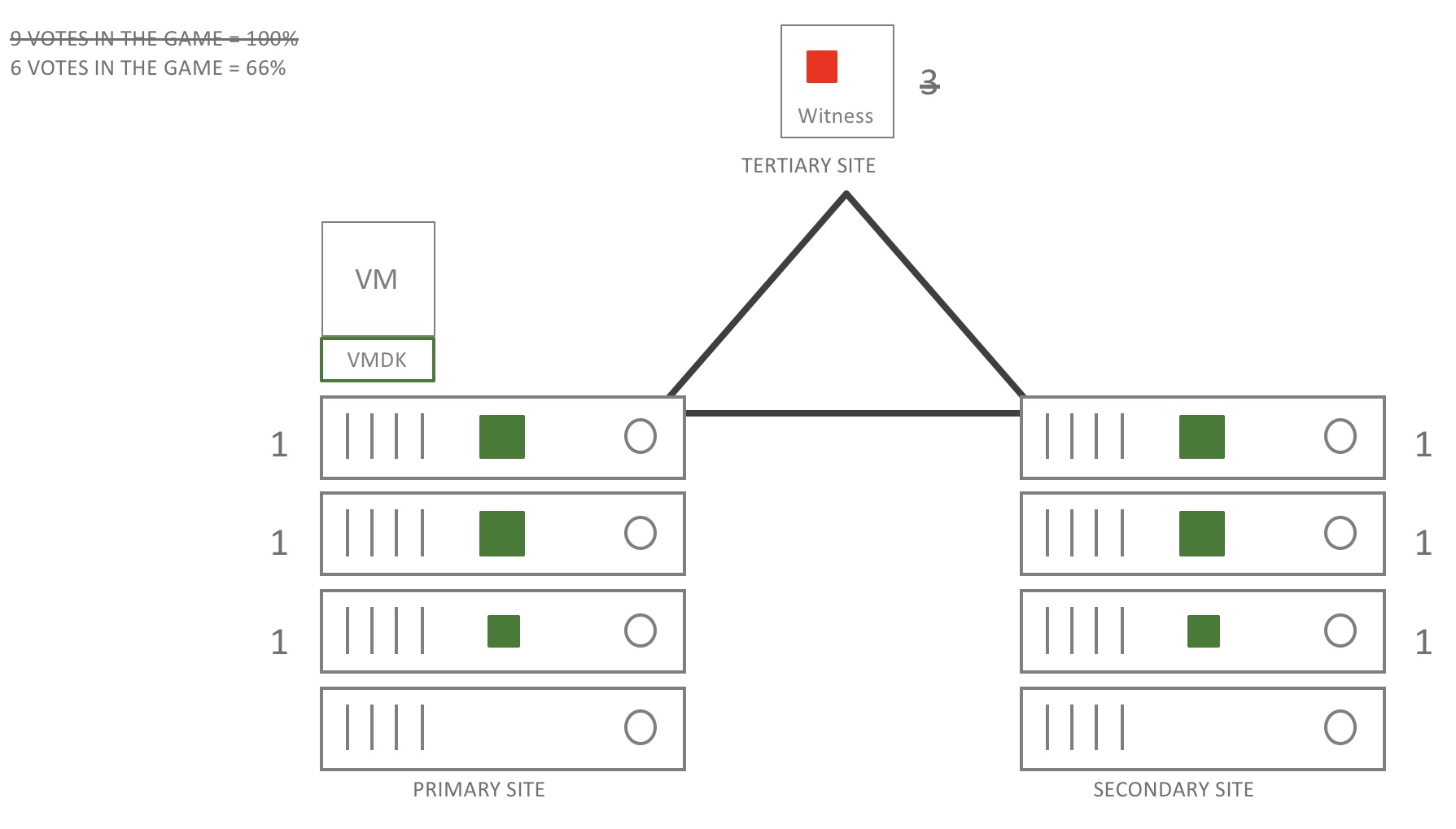
The witness has failed but no worries for the workloads. The VM is still on-line and will stay on-line. Updates to the different components are made. However, updates to the stretched cluster witness are no longer possible. 66% of all the votes are on-line so all systems “go”
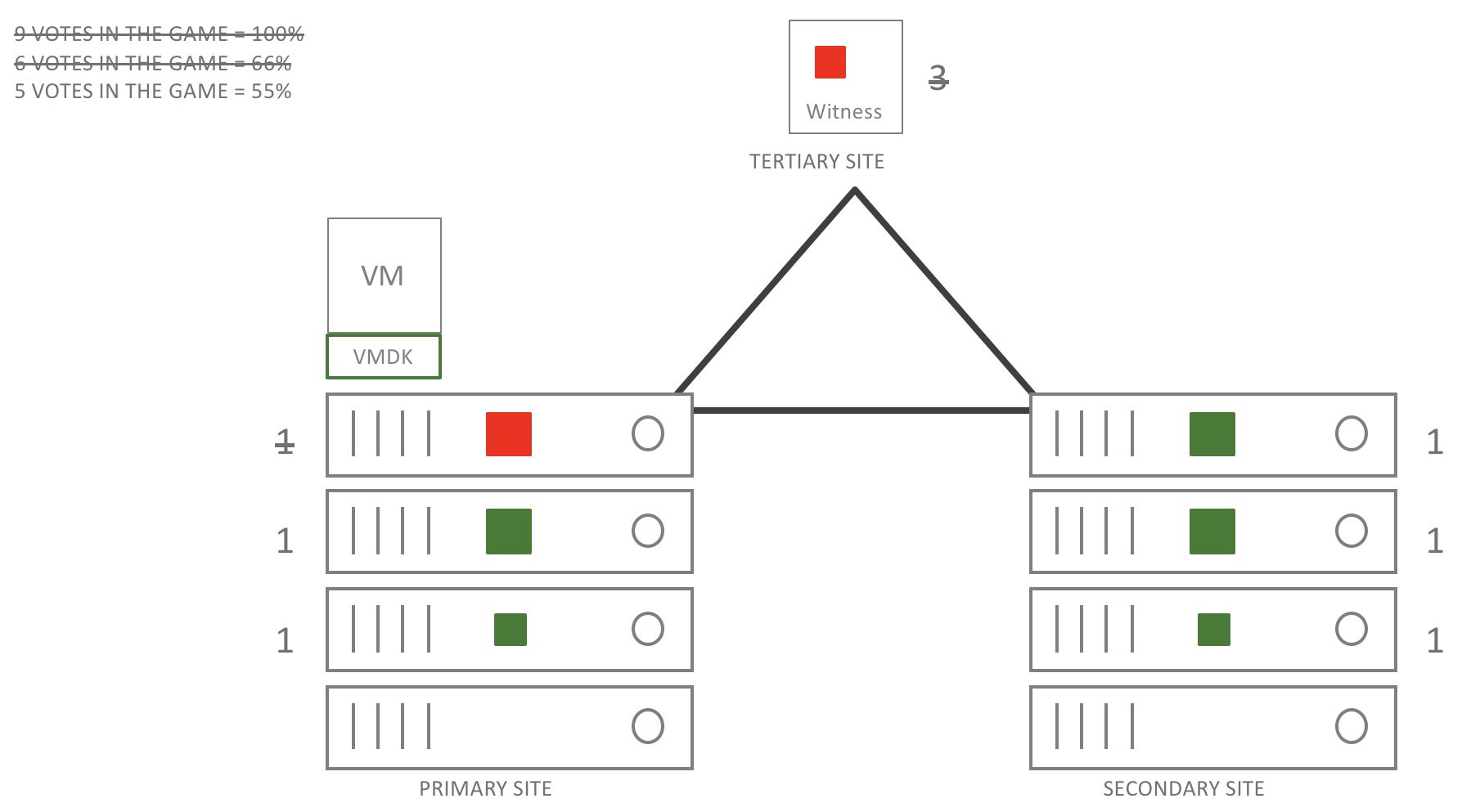
Let’s say we have a very bad day and at the exact same moment another hardware component (disk) has failed. Also, let’s imagine that there has been no time to rebuild any of the components which have failed in the previous example. As a result, out of 9 votes, 4 (3 witness & 1 HW component) votes are now down. This has the following result for the workloads: Some components of course will be absent or degraded and orange or red lights will be displayed in the HTML 5 client but, all VM’s will still be online and in the back-end a rebuild is started.
Now, let’s imagine that the day gets really bad!
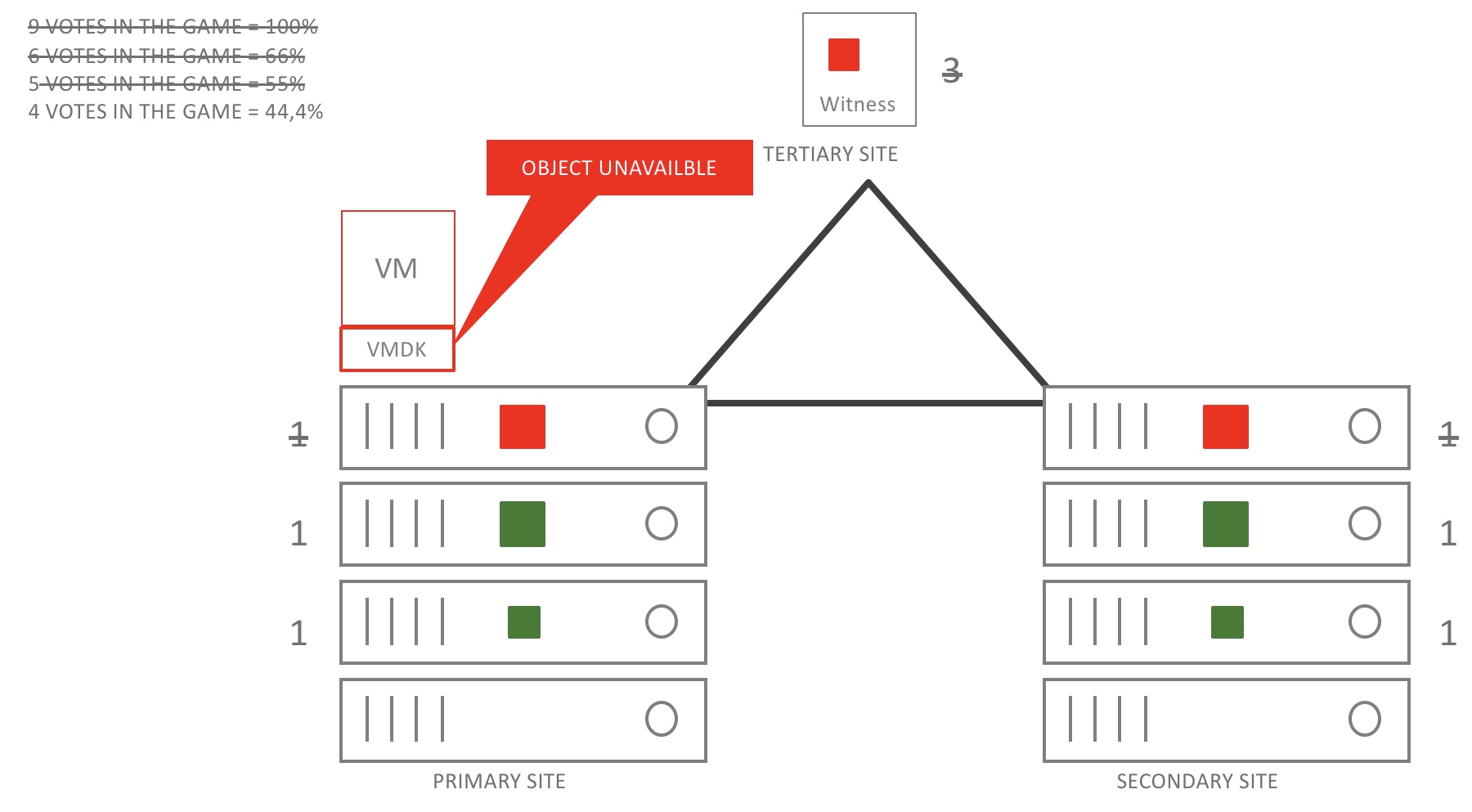
In the drawing above you see an extra failure on the secondary site. It doesn’t really matter where things fail. In this case there is still nothing fully restored or rebuilt. Out of 9 votes 5 are now down and the related object becomes unavailble. If a restore is done votes are back and service will be restored. Remember the last committed data is still there it is just in an unavailable state. VSAN is now in data-hugging mode as we need to make sure the data is safeguarded and consistent.
Ok, ok. We got this far but what if the ISL fails?
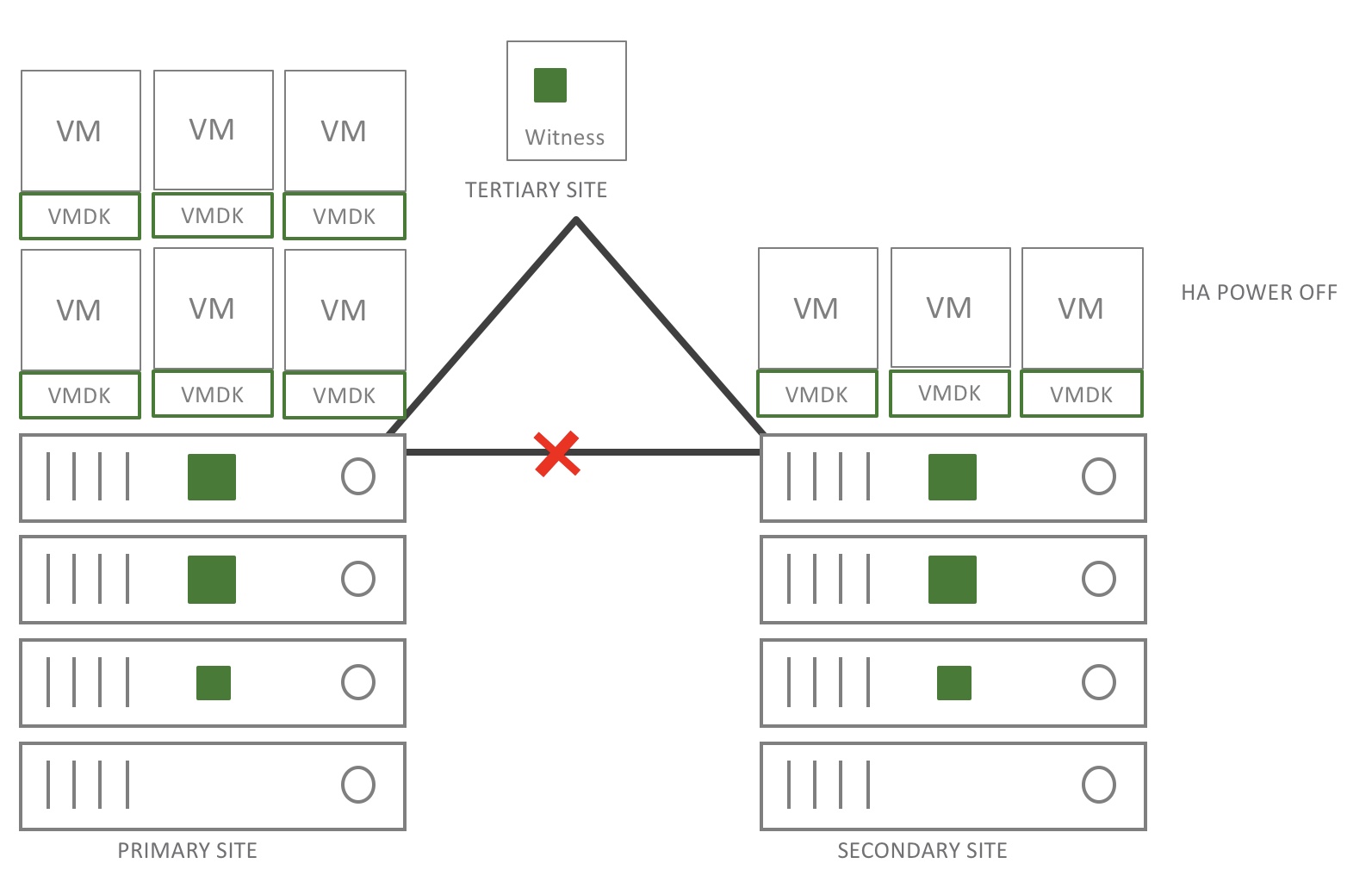
What if the ISL breaks and there is no site affinity for any VM?
To make this 100% clear, a VSAN stretched cluster uses synchronous replication between sites. So when the ISL goes down, the synchronous replication is halted. To make it easier to understand, I have added the drawing above. It displays an active-active workload spread out over the two sites. Now pay attention, when the ISL breaks, the first site and the witness are automatically forming a cluster. This will trigger HA for the workloads on the second site and thus these workloads will reboot on the primary site and restoring service as the data is still available on site 1.
What if the ISL breaks and there is site affinity for some VMs?
Now if you would have VMs that have a site affinity which allows them to run on the secondary but prevents them from running on the primary site, this would trigger a shutdown for the VMs which have a site affinity to the secondary site! Because these VMs have no objects on the primary site you would never be able to restore services for these workloads on the primary site. If you would have a site affinity linked to the primary site nothing would happen and it would be business as usual.
So depending on the workloads and the attached site affinity I would say pick the right choice as the impact might be different and not favourable for the uptime of the application. Don’t say you where not warned. You can read about it here and here and here.
When sites are partitioned due to ISL loss there’s no component reconfiguration across sites is required due to PFTT=0. In addition, as site affinity is set to secondary the VM will not be HA restarted on the preferred site, rather it will be allowed to run in place on the secondary site. This is because the object is in compliance with its policy and does not need site-quorum to run. The VM continues running.